Buffers
About buffers
Buffers are used to store binary data. You can write data to the buffer and read data from the buffer. Data is always written to the end of the buffer. The buffer will internally keep track of the reading position (which starts at 0 and increases as data is read from the buffer), but you can also change it manually.
Note
In the extension for GM Studio, I have renamed all buffer functions so they start with 'hbuffer' instead of 'buffer' to avoid conflicts. The extension for GM7/8/8.1 is not affected by this.
Data types
|
Type |
Size (bytes) |
Lowest value |
Highest value |
Resolution |
Other names |
|
int8 |
1 |
-128 |
127 |
1 |
byte, char |
|
uint8 |
1 |
0 |
255 |
1 |
unsigned byte, unsigned char |
|
int16 |
2 |
-32,768 |
32,767 |
1 |
short |
|
uint16 |
2 |
0 |
65,535 |
1 |
unsigned short, WORD |
|
int32 |
4 |
-2,147,483,648 |
2,147,483,647 |
1 |
int |
|
uint32 |
4 |
0 |
4,294,967,296 |
1 |
unsigned int, DWORD |
|
int64 |
8 |
-9,223,372,036,854,775,808 |
9,223,372,036,854,775,807 |
1 |
long long |
|
uint64 |
8 |
0 |
18,446,744,073,709,551,615 |
1 |
unsigned long long, QWORD |
|
intv |
1 to 4 |
-269,492,288 |
269,492,287 |
1 |
|
|
uintv |
1 to 4 |
0 |
538,984,575 |
1 |
|
|
float32 |
4 |
-1.7014e38 |
1.7014e38 |
~7 significant figures |
float |
|
float64 |
8 |
-8.9885e307 |
8.9885e307 |
~16 significant figures |
double |
|
string |
length+1 |
- |
- |
- |
NULL-terminated string, C string |
Game Maker uses doubles (float64) to store numbers, so you can write any number you use in GM to a buffer as float64. Note that this uses 8 bytes, so try to avoid them if possible.
-
If you know the number is an integer, use one of the integral data types.
-
If you know the number is a positive integer (greater than or equal to zero), use one of the unsigned integral data types.
-
If the number is not an integer, and high precision is not important, use float32.
intv and uintv are special integral types, their size depends on the value. For values close to zero, they will use just one byte. This makes them very useful if you want to send values that are usually relatively small but sometimes very large.
|
Bytes |
Range (intv) |
Range (uintv) |
|
1 |
-64 to 63 |
0 to 127 |
|
2 |
-8,256 to -65 / 64 to 8,255 |
128 to 16,511 |
|
3 |
-1,056,832 to -8,257 / 8,256 to 1,056,831 |
16,512 to 2,113,663 |
|
4 |
-269,492,288 to -1,056,833 / 1,056,832 to 269,492,287 |
2,113,664 to 538,984,575 |
intv and uintv are actually a prefix code. Some bits are used to indicate whether 1, 2, 3 or 4 bytes are used, and the other bits store the data. This image shows the structure for uintv:
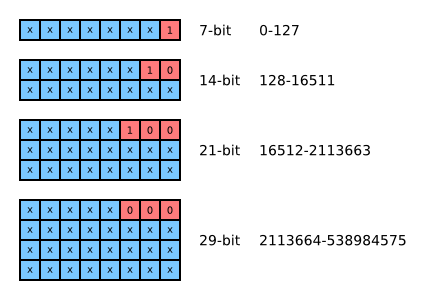
Note that the bytes are stored in little-endian order, so the red bits are always the lowest-order bits. intv is very similar: the values are first mapped to uintv and then encoded using the same system. This table shows the mapping between intv and uintv:
|
intv |
0 |
-1 |
1 |
-2 |
2 |
-3 |
3 |
-4 |
4 |
... |
|
uintv |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
... |
Usage example
Writing data to a buffer:
var buffer; // create a buffer buffer = buffer_create(); // write data to the buffer buffer_write_uint8(buffer, 42); buffer_write_uint8(buffer, 77); buffer_write_float32(buffer, 3.14); buffer_write_string(buffer, "hello world"); // save the data to a file buffer_write_to_file(buffer, "data.txt"); // destroy the buffer buffer_destroy(buffer);
Reading data from a buffer:
var buffer, a, b, c, d;
// create a buffer
buffer = buffer_create();
// read the data from the file
if !buffer_read_from_file(buffer, "data.txt") {
buffer_destroy(buffer);
show_message("Error: Reading data.txt failed! Make sure the file exists.");
exit;
}
// read data from the buffer
// this should be done in exactly the same order
a = buffer_read_uint8(buffer);
b = buffer_read_uint8(buffer);
c = buffer_read_float32(buffer);
d = buffer_read_string(buffer);
// display the result
show_message("a = "+string(a)+"#b = "+string(b)+"#c = "+string(c)+"#d = "+d);
// output:
// a = 42
// b = 77
// c = 3.14
// d = hello world
// destroy the buffer
buffer_destroy(buffer);
Functions
(h)buffer_create
(h)buffer_create()
Creates a new buffer and returns the id.
(h)buffer_destroy
(h)buffer_destroy(id)
Destroys a buffer.
-
id: The id of the buffer.
(h)buffer_exists
(h)buffer_exists(id)
Returns whether a buffer exists.
-
id: The id of the buffer.
(h)buffer_to_string
(h)buffer_to_string(id)
Returns the contents of a buffer as a string. This is not binary-safe, the string will end at the first NULL byte.
-
id: The id of the buffer.
(h)buffer_get_pos
(h)buffer_get_pos(id)
Returns the current reading position.
-
id: The id of the buffer.
(h)buffer_get_length
(h)buffer_get_length(id)
Returns the length of the buffer.
-
id: The id of the buffer.
(h)buffer_at_end
(h)buffer_at_end(id)
Returns whether the reading position is at the end of the buffer (same as buffer_get_pos()==buffer_get_length()).
-
id: The id of the buffer.
(h)buffer_get_error
(h)buffer_get_error(id)
Returns whether an error has occurred while reading. This happens when you try to read from a buffer after reaching the end (all reading functions will return 0 or "" when this happens).
-
id: The id of the buffer.
(h)buffer_clear_error
(h)buffer_clear_error(id)
Clears the error flag. After calling this function buffer_get_error will return false (until another error occurs).
-
id: The id of the buffer.
(h)buffer_clear
(h)buffer_clear(id)
Clears the buffer. This also clears the error flag.
-
id: The id of the buffer.
(h)buffer_set_pos
(h)buffer_set_pos(id, pos)
Changes the reading position of the buffer.
-
id: The id of the buffer.
-
pos: The new reading position.
(h)buffer_read_from_file
(h)buffer_read_from_file(id, filename)
Reads the contents of a file and copies them to the buffer.
-
id: The id of the buffer.
-
filename: The path to the file.
(h)buffer_read_from_file_part
(h)buffer_read_from_file_part(id, filename, pos, len)
Reads a part of a file and copies it to the buffer.
-
id: The id of the buffer.
-
filename: The path to the file.
-
pos: The position in the file (i.e. the position of the first byte, starting from 0).
-
len: The length of the part that you want to read.
(h)buffer_write_to_file
(h)buffer_write_to_file(id, filename)
Writes the contents of the buffer to a file. The file will be overwritten if it exists already.
-
id: The id of the buffer.
-
filename: The path to the file.
(h)buffer_append_to_file
(h)buffer_append_to_file(id, filename)
Appends the contents of the buffer to the end of a file. The file will be created if it doesn't exist.
-
id: The id of the buffer.
-
filename: The path to the file.
(h)buffer_rc4_crypt
(h)buffer_rc4_crypt(id,key)
Encrypts or decrypts the buffer with the RC4 encryption algorithm. Note that RC4 uses only the first 256 bytes of the key. Since RC4 is a XOR cipher, the encryption and decryption algorithm are the same. RC4 is not the most secure encryption algorithm, especially when bad keys are used, so if security is really important (rather than just obfuscation), I recommend reading the Wikipedia article first so you know what you're doing. Even though proper use of RC4 makes it impossible for others to see what the data means, it will not prevent others from changing the data (probably into complete nonsense). If data integrity is also important, you should calculate the MD5 or SHA-1 hash of the data and encrypt it along with the data so you can verify the data after decryption.
-
id: The id of the buffer.
-
key: The encryption key. This key should be unpredictable and you should never use the same key twice to encrypt different data. The time or a counter is not unpredictable. One way to get good keys is to generate them with MD5 or SHA-1 (e.g. by hashing a secret string combined with a counter).
(h)buffer_rc4_crypt_buffer
(h)buffer_rc4_crypt_buffer(id,id2)
Encrypts or decrypts the buffer with the RC4 encryption algorithm, using a second buffer as the key.
-
id: The id of the buffer.
-
id2: The id of the buffer that should be used as the key.
(h)buffer_zlib_compress
(h)buffer_zlib_compress(id)
Compresses the buffer using the 'deflate' algorithm as implemented in zlib. Compression works best for buffers that are reasonably long and have a lot of repetition and/or use some byte values more often than others (e.g. text). If you have many small buffers, it's usually better to combine them into one large buffer before compression.
-
id: The id of the buffer.
(h)buffer_zlib_uncompress
(h)buffer_zlib_uncompress(id)
Uncompresses the buffer using the 'deflate' algorithm as implemented in zlib. Uncompression can fail if the data is corrupted. The function will return whether uncompression was successful.
-
id: The id of the buffer.
(h)buffer_read_int8
(h)buffer_read_int8(id)
Reads a 8-bit signed integer from the buffer.
-
id: The id of the buffer.
(h)buffer_read_uint8
(h)buffer_read_uint8(id)
Reads a 8-bit unsigned integer from the buffer.
-
id: The id of the buffer.
(h)buffer_read_int16
(h)buffer_read_int16(id)
Reads a 16-bit signed integer from the buffer.
-
id: The id of the buffer.
(h)buffer_read_uint16
(h)buffer_read_uint16(id)
Reads a 16-bit unsigned integer from the buffer.
-
id: The id of the buffer.
(h)buffer_read_int32
(h)buffer_read_int32(id)
Reads a 32-bit signed integer from the buffer.
-
id: The id of the buffer.
(h)buffer_read_uint32
(h)buffer_read_uint32(id)
Reads a 32-bit unsigned integer from the buffer.
-
id: The id of the buffer.
(h)buffer_read_int64
(h)buffer_read_int64(id)
Reads a 64-bit signed integer from the buffer.
-
id: The id of the buffer.
(h)buffer_read_uint64
(h)buffer_read_uint64(id)
Reads a 64-bit unsigned integer from the buffer.
-
id: The id of the buffer.
(h)buffer_read_intv
(h)buffer_read_intv(id)
Reads a variable-size signed integer from the buffer.
-
id: The id of the buffer.
(h)buffer_read_uintv
(h)buffer_read_uintv(id)
Reads a variable-size unsigned integer from the buffer.
-
id: The id of the buffer.
(h)buffer_read_float32
(h)buffer_read_float32(id)
Reads a 32-bit floating point number ('float') from the buffer.
-
id: The id of the buffer.
(h)buffer_read_float64
(h)buffer_read_float64(id)
Reads a 64-bit floating point number ('double') from the buffer.
-
id: The id of the buffer.
(h)buffer_write_int8
(h)buffer_write_int8(id, value)
Writes a 8-bit signed integer to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_write_uint8
(h)buffer_write_uint8(id, value)
Writes a 8-bit unsigned integer to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_write_int16
(h)buffer_write_int16(id, value)
Writes a 16-bit signed integer to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_write_uint16
(h)buffer_write_uint16(id, value)
Writes a 16-bit unsigned integer to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_write_int32
(h)buffer_write_int32(id, value)
Writes a 32-bit signed integer to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_write_uint32
(h)buffer_write_uint32(id, value)
Writes a 32-bit unsigned integer to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_write_int64
(h)buffer_write_int64(id, value)
Writes a 64-bit signed integer to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_write_uint64
(h)buffer_write_uint64(id, value)
Writes a 64-bit unsigned integer to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_write_intv
(h)buffer_write_intv(id, value)
Writes a variable-size signed integer to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_write_uintv
(h)buffer_write_uintv(id, value)
Writes a variable-size unsigned integer to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_write_float32
(h)buffer_write_float32(id, value)
Writes a 32-bit floating point number ('float') to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_write_float64
(h)buffer_write_float64(id, value)
Writes a 64-bit floating point number ('double') to the buffer.
-
id: The id of the buffer.
-
value: The value.
(h)buffer_read_string
(h)buffer_read_string(id)
Reads a string from the buffer (NULL-terminated).
-
id: The id of the buffer.
(h)buffer_write_string
(h)buffer_write_string(id, string)
Writes a string to the buffer (NULL-terminated).
-
id: The id of the buffer.
-
string: The string.
(h)buffer_read_data
(h)buffer_read_data(id, len)
Reads a string with a fixed length from the buffer (not NULL-terminated).
-
id: The id of the buffer.
-
len: The length of the string.
(h)buffer_write_data
(h)buffer_write_data(id, string)
Writes a string with a fixed length to the buffer (not NULL-terminated).
-
id: The id of the buffer.
-
string: The string.
(h)buffer_read_hex
(h)buffer_read_hex(id, len)
Reads a number of bytes from the buffer and converts the result to a hexadecimal string.
-
id: The id of the buffer.
-
len: The number of bytes to be read.
(h)buffer_write_hex
(h)buffer_write_hex(id, string)
Converts a hexadecimal string to bytes and writes the result to the buffer.
-
id: The id of the buffer.
-
string: A hexadecimal string.
(h)buffer_read_base64
(h)buffer_read_base64(id, len)
Reads a number of bytes from the buffer and converts the result to a base64-encoded string. The data is encoded with 64 characters per line, CR+LF line endings, and uses + and / for index 62 and 63.
-
id: The id of the buffer.
-
len: The number of bytes to be read.
(h)buffer_write_base64
(h)buffer_write_base64(id, string)
Converts a base64-encoded string to bytes and writes the result to the buffer. The decoder understands + and /, but also - and _. Padding (=) at the end is allowed but not required. Padding anywhere else in the string is also allowed and handled properly (i.e. concatenated base64-encoded strings will be decoded correctly). Any other characters (e.g. newlines, spaces and tabs) are skipped.
-
id: The id of the buffer.
-
string: A base64-encoded string.
(h)buffer_write_buffer
(h)buffer_write_buffer(id, id2)
Writes the contents of another buffer to this buffer.
-
id: The id of the destination buffer.
-
id2: The id of the source buffer.
(h)buffer_write_buffer_part
(h)buffer_write_buffer_part(id, id2, pos, len)
Writes a part of the contents of another buffer to this buffer.
-
id: The id of the destination buffer.
-
id2: The id of the source buffer.
-
pos: The starting position.
-
len: The length.
Comments
40hz |
Comment #1: Mon, 22 Jul 2013, 12:41 (GMT+1, DST) buffer_write_hex doesn't work for me. While buffer_read_hex properly reads saved 16-byte md5 hash and returns a 32-byte string, writing function outputs every character separately resulting in 32-bytes written into the buffer. |
Maarten BaertAdministrator |
Comment #2: Tue, 23 Jul 2013, 20:40 (GMT+1, DST) Quote: 40hz
buffer_write_hex doesn't work for me. While buffer_read_hex properly reads saved 16-byte md5 hash and returns a 32-byte string, writing function outputs every character separately resulting in 32-bytes written into the buffer. Apparently I typed BinToHex instead of HexToBin in that function. I've fixed it now (version 2.3 release 5). |
40hz |
Comment #3: Mon, 29 Jul 2013, 12:11 (GMT+1, DST) Quote: Maarten Baert
Apparently I typed BinToHex instead of HexToBin in that function. I've fixed it now (version 2.3 release 5). Thank you. [img]http://s11.postimg.org/79n04k4fn/pinkie_pie_smile.png[/img] |
Knol1100 |
Comment #4: Mon, 18 May 2015, 14:19 (GMT+1, DST) Hallo Maarten, Wij proberen om een audiobestand op te slaan als bestand op de computer. Groet, |
Maarten BaertAdministrator |
Comment #5: Wed, 20 May 2015, 2:04 (GMT+1, DST) Quote: Knol1100
Hallo Maarten, Wij proberen om een audiobestand op te slaan als bestand op de computer. Groet, Dat is een kwestie van het WAV-formaat correct implementeren. Ik zou gewoon een wav-bestandje met het juiste formaat aanmaken via bv. Audacity en dan kijken wat de header en footer is die in dat bestand zitten. Dan uitzoeken welke bytes de lengte, samplerate en aantal kanalen geven. De rest moet je op zich niet aanpassen. Dat kan je dan imiteren in je code. Ik heb zoiets al eerder gedaan, maar dat was niet in GM. Ik wil gerust vragen beantwoorden over deze DLL, maar ik ben hier niet om andermans code te debuggen ;). |
Jmscreator |
Comment #6: Mon, 23 Jan 2017, 17:16 (GMT+1, DST) Hello! I have found an interesting buffer overflow bug with http-dll-2 buffers. When reading from a buffer, if you read more than what is in the buffer, zero is returned(this isn't the issue I'm referring to). Now I do my best to write clean code, and I make it nearly impossible for this to happen, but with sockets, and data that can sometimes glitch once in a great while, there is still the possibility for a buffer read to read outside of the buffer size. while(!buffer_at_end(buf)){
...loop through commands...
}
The problem is, under the right circumstances, buffer_at_end(buf) is returning false even though it's at the end of the buffer! I did a series of tests to get to this conclusion: Quote
If you read an intX value from a buffer that has 1 intY value written to it, the read position starts at the beginning (0), and X(the integer size you are reading) is greater than Y(the integer size that was written), buffer_at_end() for that buffer will return false. Here is a sequential code run that I did: buf = buffer_create(); buffer_write_uint8(buf, 10); (buffer_at_end(buf) == false) //This is correct buffer_read_uint8(buf) == 10 (buffer_at_end(buf) == true) //This is correct buffer_read_uint8(buf) == 0; (buffer_at_end(buf) == true) //This is correct //Here is where the problem happens: buffer_clear(buf); buffer_write_uint8(buf, 10); (buffer_read_uint16(buf) == 0) //This is correct - but: reading an integer value that is larger than the written integer at the end of the buffer causes an issue: (buffer_at_end(buf) == false) //This is incorrect! It has surpassed the buffer size, and should be true! But it is not. (buffer_read_uint8(buf) == 0) (buffer_at_end(buf) == false) //This is still incorrect Now because it returns false, while(!buffer_at_end(buf)) will loop forever no matter how many times you read from the buffer. I implement a timeout now, so that if it does happen, my game doesn't crash. I hope this helps you out! And that you may provide a fix at some point. |
Maarten BaertAdministrator |
Comment #7: Wed, 25 Jan 2017, 23:42 (GMT+1, DST) Quote: Jmscreator
When reading from a buffer, if you read more than what is in the buffer, zero is returned(this isn't the issue I'm referring to). Now I do my best to write clean code, and I make it nearly impossible for this to happen, but with sockets, and data that can sometimes glitch once in a great while, there is still the possibility for a buffer read to read outside of the buffer size. As far as I can tell there is no bug here, you just misunderstand how buffers work. If your buffer has one byte remaining, and you try to read a type that is two bytes large, nothing is read, the error flag is set, and the function just returns a default value (0). The position does not change. So no matter how many times you call buffer_read_uint16, you will never read that last byte. What you should do instead is call buffer_get_error after reading a message to verify that nothing went wrong. Situations like this will set the error flag, and it won't be cleared until you call buffer_clear_error or buffer_clear. Also, as long as the error flag is set, all read functions will return zero (or empty strings in some cases). Last modified: Wed, 25 Jan 2017, 23:44 (GMT+1, DST) |
Jmscreator |
Comment #8: Sun, 19 Mar 2017, 5:41 (GMT+1, DST) Quote: Maarten Baert
Quote: Jmscreator
When reading from a buffer, if you read more than what is in the buffer, zero is returned(this isn't the issue I'm referring to). Now I do my best to write clean code, and I make it nearly impossible for this to happen, but with sockets, and data that can sometimes glitch once in a great while, there is still the possibility for a buffer read to read outside of the buffer size. As far as I can tell there is no bug here, you just misunderstand how buffers work. If your buffer has one byte remaining, and you try to read a type that is two bytes large, nothing is read, the error flag is set, and the function just returns a default value (0). The position does not change. So no matter how many times you call buffer_read_uint16, you will never read that last byte. What you should do instead is call buffer_get_error after reading a message to verify that nothing went wrong. Situations like this will set the error flag, and it won't be cleared until you call buffer_clear_error or buffer_clear. Also, as long as the error flag is set, all read functions will return zero (or empty strings in some cases). Thank you for informing me about this! I just saw this reply today. |
Ajax_cript |
Comment #9: Tue, 26 May 2020, 1:17 (GMT+1, DST) Hello! I'm using Http Dll 2 for GM8.1 and I have few qestions. 1. Is there a missing line in the "Usage example" when reading data from a buffer? I can see file missing error handling, but I can't find, where do you read data from a file. 2. For buffer_rc4_crypt it says "Encrypts or decrypts the buffer". How does game know when encrypting or decypting needed? I mean, ther's no buffer_rc4_decrypt or something, so how can I properly decrypt a buffer? Last modified: Tue, 26 May 2020, 12:22 (GMT+1, DST) |
Maarten BaertAdministrator |
Comment #10: Tue, 26 May 2020, 16:13 (GMT+1, DST) Quote: Ajax_cript
Hello! I'm using Http Dll 2 for GM8.1 and I have few qestions. 1. Is there a missing line in the "Usage example" when reading data from a buffer? I can see file missing error handling, but I can't find, where do you read data from a file. 2. For buffer_rc4_crypt it says "Encrypts or decrypts the buffer". How does game know when encrypting or decypting needed? I mean, ther's no buffer_rc4_decrypt or something, so how can I properly decrypt a buffer? 1. buffer_read_from_file does the actual reading and returns whether it was successful. 2. RC4 is a stream cipher, so encrypting and decrypting is the same operation. If you give it plain data it will be encrypted, if you then give it the same data again with the same key it will be decrypted. Last modified: Tue, 26 May 2020, 16:14 (GMT+1, DST) |
Ajax_cript |
Comment #11: Tue, 26 May 2020, 18:24 (GMT+1, DST) Thank you! |
Ajax_cript |
Comment #12: Wed, 27 May 2020, 11:03 (GMT+1, DST) I have another one question: I made a save file like this: buffer_save = buffer_create(); buffer_write_string(buffer_save,ds_list_write(save_list)); buffer_zlib_compress(buffer_save) buffer_rc4_crypt(buffer_save,'test') buffer_write_to_file(buffer_save,'test.txt'); buffer_destroy(buffer_save); On loading I do: buffer_load = buffer_create() buffer_read_from_file(buffer_load,'test.txt') buffer_rc4_crypt(buffer_load,'test') buffer_zlib_uncompress(buffer_load) ds_list_read(load_list,buffer_read_string(buffer_load)) buffer_destroy(buffer_load) This works very well, and in the end I have 3kb test.txt. buffer_clear(buff)
if file_exists('test.txt') then
{
buffer_read_from_file(buff,'test.txt')
player_save = buffer_read_string(buff)
}
else player_save = 'null'
buffer_clear(buff)
buffer_write_uint8(buff,mid)
buffer_write_uint32(buff, player_id)
buffer_write_string(buff, player_save)
socket_write_message(server, buff);
And this on server: pid = buffer_read_unit32(buff)
psave= buffer_read_string(buff)
if psave <> "null" then
{
txt=file_text_open_write("u"+string(pid)+".txt");
file_text_write_string(txt,string(psave));
file_text_close(txt)
}
I do recieve some data and save it to file on server, but this server save file is not equal to original player's save file. Last modified: Wed, 27 May 2020, 19:10 (GMT+1, DST) |
Maarten BaertAdministrator |
Comment #13: Thu, 28 May 2020, 0:53 (GMT+1, DST) Quote: Ajax_cript
I have another one question: I made a save file like this: buffer_save = buffer_create(); buffer_write_string(buffer_save,ds_list_write(save_list)); buffer_zlib_compress(buffer_save) buffer_rc4_crypt(buffer_save,'test') buffer_write_to_file(buffer_save,'test.txt'); buffer_destroy(buffer_save); On loading I do: buffer_load = buffer_create() buffer_read_from_file(buffer_load,'test.txt') buffer_rc4_crypt(buffer_load,'test') buffer_zlib_uncompress(buffer_load) ds_list_read(load_list,buffer_read_string(buffer_load)) buffer_destroy(buffer_load) This works very well, and in the end I have 3kb test.txt. buffer_clear(buff)
if file_exists('test.txt') then
{
buffer_read_from_file(buff,'test.txt')
player_save = buffer_read_string(buff)
}
else player_save = 'null'
buffer_clear(buff)
buffer_write_uint8(buff,mid)
buffer_write_uint32(buff, player_id)
buffer_write_string(buff, player_save)
socket_write_message(server, buff);
And this on server: pid = buffer_read_unit32(buff)
psave= buffer_read_string(buff)
if psave <> "null" then
{
txt=file_text_open_write("u"+string(pid)+".txt");
file_text_write_string(txt,string(psave));
file_text_close(txt)
}
I do recieve some data and save it to file on server, but this server save file is not equal to original player's save file. The functions buffer_read_string and buffer_write_string use null-terminated strings, meaning that the end of the string is marked by a null (zero) byte. Your file contains binary data which likely contains null bytes, so this won't work. Also, you can't transfer a binary string between Game Maker and an extension for the same reason. What you need to do instead is use the function buffer_write_buffer or buffer_write_buffer_part to copy the content of one buffer to the other. Also, there is no need to save the file first, you can also send the buffer directly to the server. You should probably prefix the compressed data with the size (e.g. as uint32 or uintv), otherwise the receiver won't know how many bytes to read. Alternatively you can use buffer_get_pos and buffer_get_length in order to calculate how many bytes are left in the buffer, but that only works if the compressed data is the last thing stored in the buffer. PS: You will get better compression if you store the values from the ds_list into the buffer one by one in an appropriate format, rather than converting the entire ds_list to a string. Last modified: Thu, 28 May 2020, 0:57 (GMT+1, DST) |
Ajax_cript |
Comment #14: Thu, 28 May 2020, 12:16 (GMT+1, DST) Made new code on client: buffer_clear(buff)
buffer_write_uint8(buff,mid)
buffer_write_uint32(buff, player_id)
buffer_clear(buff_save)
if file_exists('test.txt') then
{
buffer_read_from_file(buff_save,'test.txt')
buffer_write_buffer(buff,buff_save)
}
else buffer_write_string(buff, 'null')
socket_write_message(server, buff);
And this on server: pid = buffer_read_unit32(buff) psave= buffer_read_string(buff) save_data = buffer_read_data(buff,buffer_get_length(buff) - buffer_get_pos(buff)) buffer_write_data(buffer_save,save_data) buffer_write_to_file(buffer_save,'test.txt'); This faild, file on server is still only a part of original. Last modified: Thu, 28 May 2020, 12:22 (GMT+1, DST) |
Maarten BaertAdministrator |
Comment #15: Thu, 28 May 2020, 15:58 (GMT+1, DST) Quote: Ajax_cript
Made new code on client: buffer_clear(buff)
buffer_write_uint8(buff,mid)
buffer_write_uint32(buff, player_id)
buffer_clear(buff_save)
if file_exists('test.txt') then
{
buffer_read_from_file(buff_save,'test.txt')
buffer_write_buffer(buff,buff_save)
}
else buffer_write_string(buff, 'null')
socket_write_message(server, buff);
And this on server: pid = buffer_read_unit32(buff) psave= buffer_read_string(buff) save_data = buffer_read_data(buff,buffer_get_length(buff) - buffer_get_pos(buff)) buffer_write_data(buffer_save,save_data) buffer_write_to_file(buffer_save,'test.txt'); This faild, file on server is still only a part of original. The problem is this: save_data = buffer_read_data(buff,buffer_get_length(buff) - buffer_get_pos(buff)) buffer_write_data(buffer_save,save_data) Although the data is not null-terminated, Game Maker cannot handle binary strings. It's Game Maker itself which is dropping part of the data, not the DLL. You need to use buffer_write_buffer_part to copy the data to buffer_save: buffer_write_buffer_part(buffer_save,buff,buffer_get_pos(buff),buffer_get_length(buff) - buffer_get_pos(buff)) Last modified: Thu, 28 May 2020, 15:59 (GMT+1, DST) |
Ajax_cript |
Comment #16: Mon, 1 Jun 2020, 15:29 (GMT+1, DST) Yes, it worked, thank you! |